
Clickhouse: ¡Chango!
En este post vamos a ver una de las DBs OLAP que se jacta de permitirnos operar como ninguna otra: Clickhouse. Haremos un paseo por sus virtudes, falencias y sus tecnologia increiblemente veloz.
Clickhouse
ClickHouse es un sistema de gestión de bases de datos (DBMS), con una interfaz SQL muy desarrollada, se auto definen como: de alto rendimiento y orientado a columnas para procesamiento analítico en línea (OLAP). Está disponible su version de código abierto, tambien releases de compañias que ofrecen de alguna manera soporte sobre sus versiones, así como también hay disponible ofertas IasS.
ENGINE MergeTree
- Puede ser considerado el engine por defecto de Clickhouse.
- Ordena los datos por indice primario (sparse index).
- Los datos pueden ser particionados (partitions + parts).
- Sentencia de creación:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [[NOT] NULL] [DEFAULT|MATERIALIZED|ALIAS|EPHEMERAL expr1] [COMMENT ...] [CODEC(codec1)] [TTL expr1] [PRIMARY KEY], name2 [type2] [[NOT] NULL] [DEFAULT|MATERIALIZED|ALIAS|EPHEMERAL expr2] [COMMENT ...] [CODEC(codec2)] [TTL expr2] [PRIMARY KEY], ... INDEX index_name1 expr1 TYPE type1(...) [GRANULARITY value1], INDEX index_name2 expr2 TYPE type2(...) [GRANULARITY value2], ... PROJECTION projection_name_1 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY]), PROJECTION projection_name_2 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY]) ) ENGINE = MergeTree() ORDER BY expr [PARTITION BY expr] [PRIMARY KEY expr] [SAMPLE BY expr] [TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx' [, ...] ] [WHERE conditions] [GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ] ] [SETTINGS name=value, ...]- ENGINE — El engine MergeTree() no lleva parámetros.
- ORDER BY — La clave de ordenamiento (sorting key) - Clickhouse usa la sorting key para determinar como se almacena la información en disco, además sirve en engines de la familia MergeTree para funcionalidades específicas de cada tipo, por ejemplo sirve como clave de agregación en AggregatingMergeTree o de deduplicación en CollapsingMergeTree. Se usa como como clave primaria si PRIMARY KEY no es provista)
- PARTITION BY — La clave de particionado. Opcional. Por ejemplo si se desea particionar por mes: toYYYYMM(date_column), donde date_column es del tipo de dato Date. Las particiones son nomencladas de la forma "YYYYMM".
- PRIMARY KEY — Opcional. Siempre es igual o un prefijo de la sorting key. En muchos casos es innesesario definir el PRIMARY KEY, toma por defecto ORDER BY. Sirve para armar el indice propiamente dicho (primary.idx).
¿Cuando difieren ORDER BY y PRIMARY KEY?
Si por ejemplo en algun momento se requiere agregar una columna mas a una clave de agregación, puede ser recomendable solo modificar la ORDER BY (o sorting key) mediante un ALTER TABLE, manteniendo la PRIMARY KEY, y por lo tanto su archivo de indices, sin modificar. Ahorrandonos de esta manera una reindexación completa, ya que la antigua PK será prefijo de la nueva sorting key, situación aceptable para el funcionamiento del motor. Obiamente la estrategia va a depender de la cardinalidad y el uso como filtro que se le quiera dar a la nueva columna.
Sorting key vs Primary key
Sorting key defines order in which data will be stored on disk, while primary key defines how data will be structured for queries. Usually those are the same (and in this case you can omit PRIMARY KEY expression, Clickhouse will take that info from ORDER BY expression). link
Ejemplo
CREATE TABLE my_base_raw.transactions_raw(
`transaction_id` Int64,
`user_id` Int32,
`created_at` DateTime(3),
`type` String,
`amount` Decimal(10,2),
`__ver` Int64) ENGINE = MergeTree()
ORDER BY (transaction_id)
PARTITION BY toYYYYMM(timestamp)
Particiones e Indices
- A su vez podemos listar las diferentes particiones/parts de cada tabla en Clickhouse consultando la tabla de sistema
system.parts.
SELECT
partition,
name,
active
FROM system.parts
WHERE (table = 'transactions_raw') AND (partition = '202310')
Query id: 6b6aa9ec-fc61-4217-bd47-a3c4fd9400b5
┌─partition─┬─name────────────────────────┬─active─┐
│ 202310 │ 202310_4475842_4490464_1414 │ 1 │
│ 202310 │ 202310_4490465_4511646_1317 │ 1 │
│ 202310 │ 202310_4511647_4515242_1330 │ 1 │
│ 202310 │ 202310_4515243_4515584_174 │ 0 │
│ 202310 │ 202310_4515243_4515585_175 │ 0 │
│ 202310 │ 202310_4515243_4515593_183 │ 0 │
│ 202310 │ 202310_4515243_4515594_184 │ 0 │
│ 202310 │ 202310_4515243_4515595_185 │ 1 │
│ 202310 │ 202310_4515595_4515595_0 │ 0 │
│ 202310 │ 202310_4515596_4515596_0 │ 1 │
│ 202310 │ 202310_4515597_4515597_0 │ 1 │
│ 202310 │ 202310_4515598_4515598_0 │ 1 │
│ 202310 │ 202310_4515599_4515599_0 │ 1 │
└───────────┴─────────────────────────────┴────────┘
Desglose del nombre de la parte: 202310_4515243_4515595_185:
202310es el nombre de la partición.4515243es el número mínimo de la PK del bloque de datos.4515595es el número máximo de la PK del bloque de datos.185es la versión de mutación (si una parte ha mutado).
¿Como funcionan los indices esparcidos?
Dado el siguiente indice dentro de una partición de una tabla:  Si en una query utilizamos los siguientes filtros en la dondición WHERE, la poda o pruning inicial sería:
Si en una query utilizamos los siguientes filtros en la dondición WHERE, la poda o pruning inicial sería:
- CounterID in ('a', 'h') → ranges of marks [0, 3) and [6, 8).
- CounterID IN ('a', 'h') AND Date = 3 → ranges of marks [2, 3) and [7, 8).
- Date = 3 → range of marks [1, 10].
Representación gráfica del indice primario y estrategia de almacenamiento
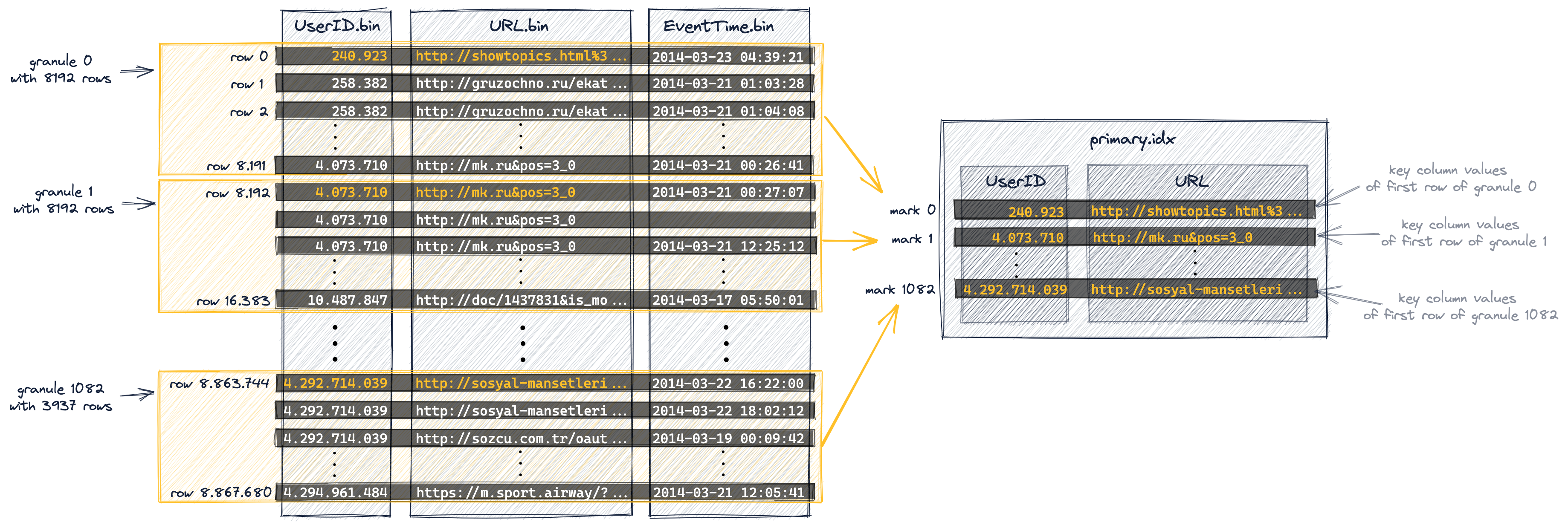
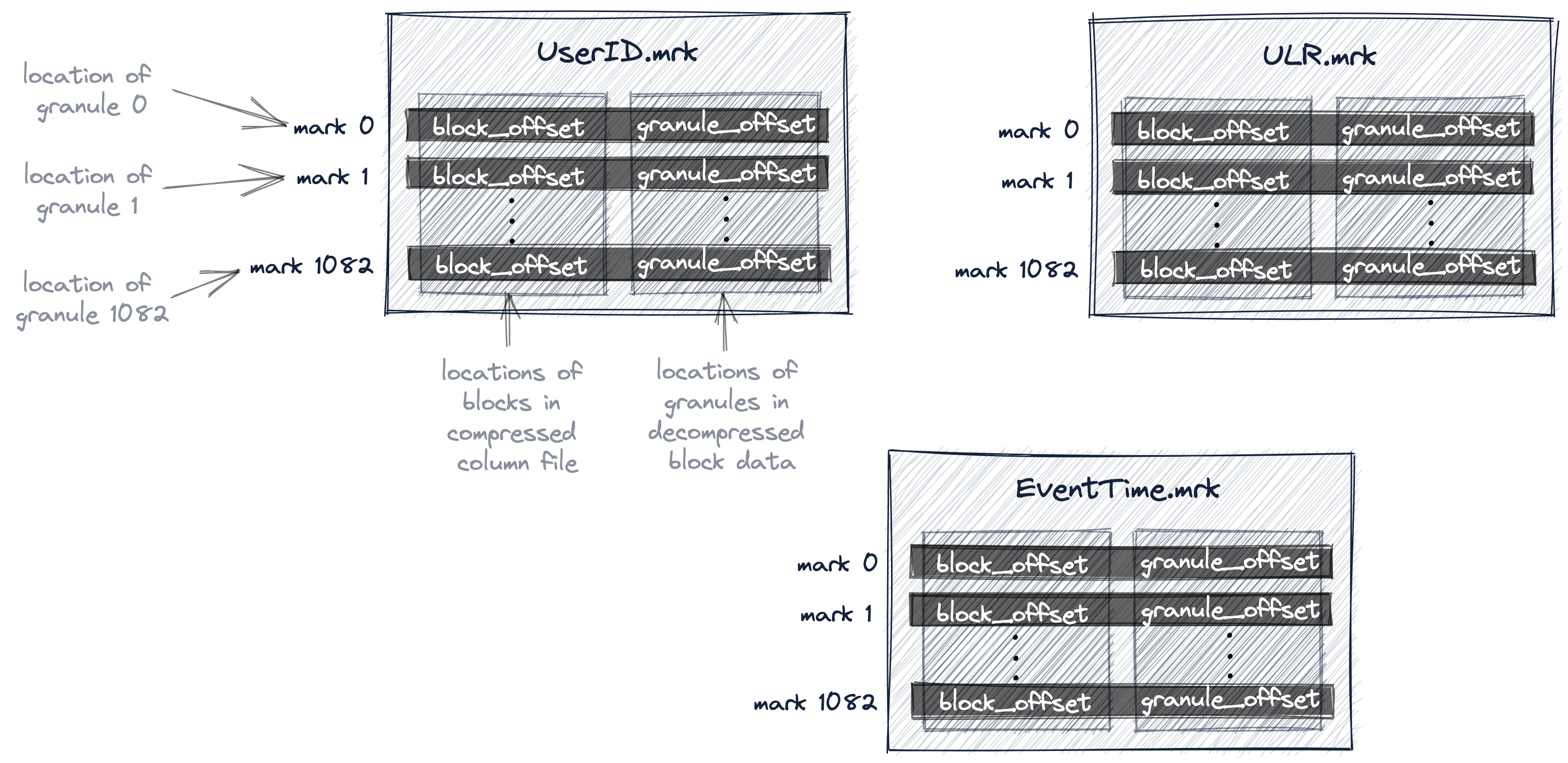
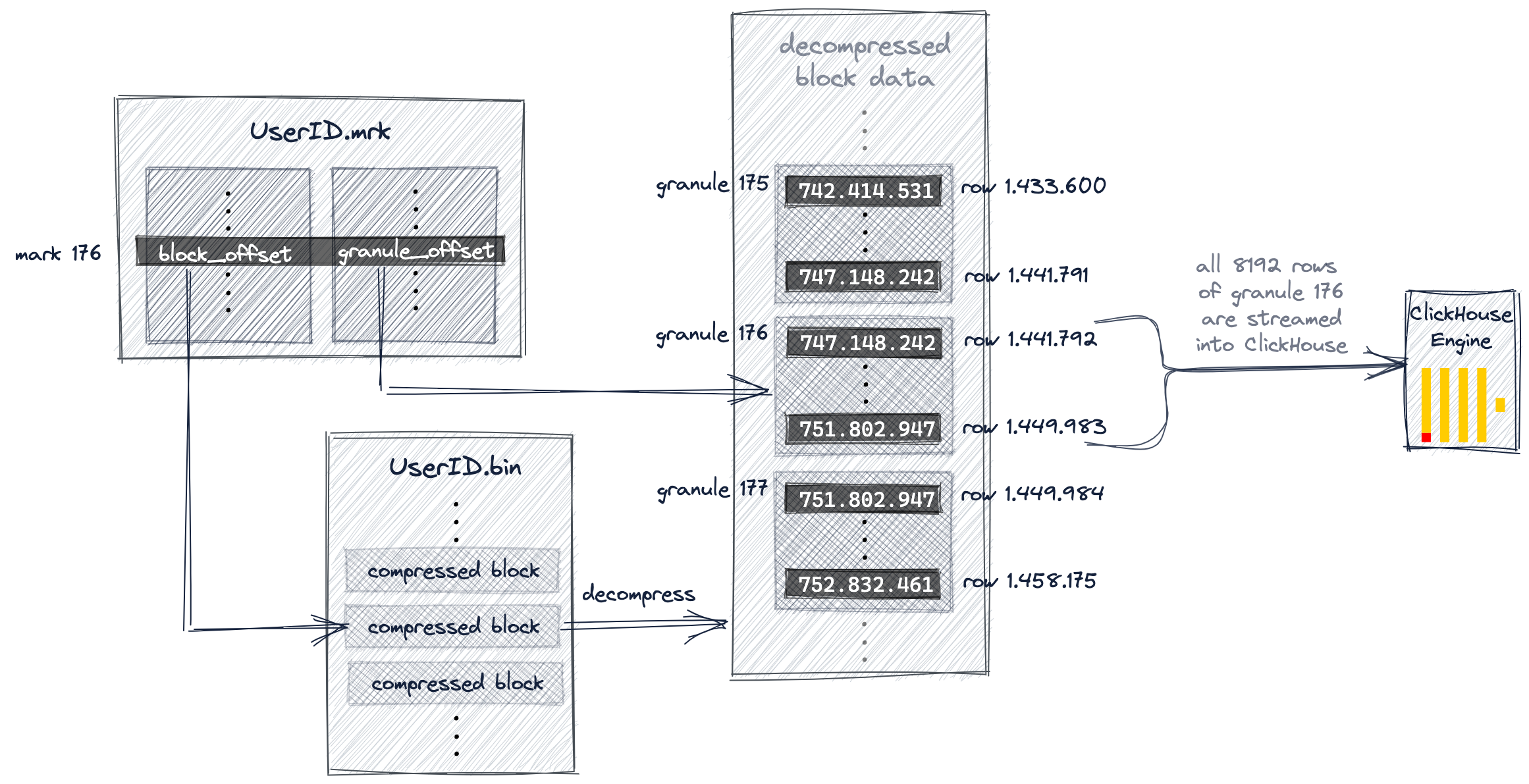
ENGINE Kafka
Las tablas definidas con ENGINE = Kafka hacen las veces de consumidores de eventos en topics, y las cuales no sirven de almacenamiento permanente.
MaterializedViews
En Clickhouse las vistas materializadas (MaterializedViews) funcionan como "triggers" de la tabla fuente de la consulta, es decir la db ofrece una funcionalidad reactiva ante nuevas filas. Lectura