
Building a real-time data pipeline: Syncing MySQL and ClickHouse through Kafka
Reporting engines stand as indispensable components in the landscape of information systems. They empower users with access to data, facilitating rapid analysis and informed decision-making.
In this post, we delve into the technical intricacies of syncing a MySQL database with ClickHouse, a columnar oriented engine. This strategic approach lays the foundation for building a robust, scalable, and high-performance analytical engine proficient at handling substantial data volumes.
"Big Data, that's it! Right?"
Every day, we witness the exponential growth of information stored, trafficked, and processed. Let's delve into the complexity by considering the formidable task of gauging the efficacy of a new feature on the frontend of one of the most widely utilized audiovisual playback platforms.
For the sake of illustration, let's assume we have a user base of 1 million individuals per day. We introduce the new functionality to a certain percentage (X) of these users, who, on average, interact with it at least four times during their daily sessions. If our A/B test employs a 50/50 distribution, half of the users will exhibit no activity logs, while the other half will generate a minimum of four logs per day. This translates to a staggering 60 million logs per month. After a three-month experimental period rise a colossal 180 million rows that we aim to analyze to validate the effectiveness of our feature.
The choice of a database engine becomes crucial, varying depending on the software solution offered. While it may seem unconventional to log user interactions into a transactional database, let's consider an illustrative example within the context of a real-life pipeline. Imagine our project utilizes a MySQL Server, logging each interaction. As previously mentioned, in the worst-case scenario, we analyze the feature's performance quarterly, dealing with approximately 180 million rows. If our queries contend for resources, irrespective of our hardware's capacity, it becomes apparent that querying such vast information within a traditional RDBMS could pose challenges.
In this post, we will explore how to create a synchronization pipeline between our MySQL source database and our ClickHouse analytics database. Additionally, we will use Kafka as the means of synchronization.
Column-Oriented vs Row-Oriented
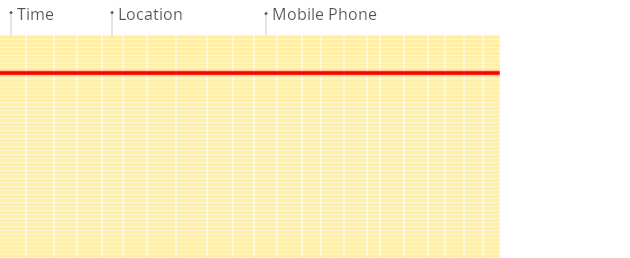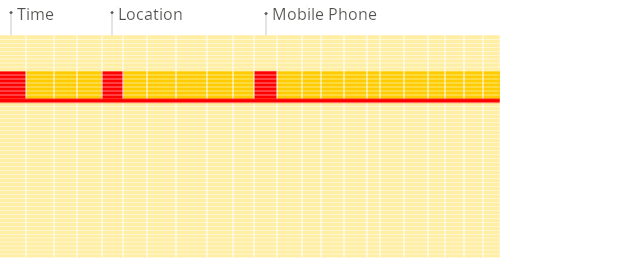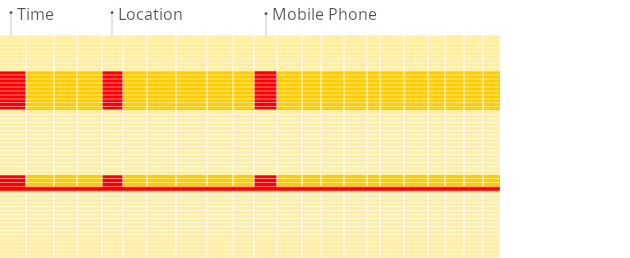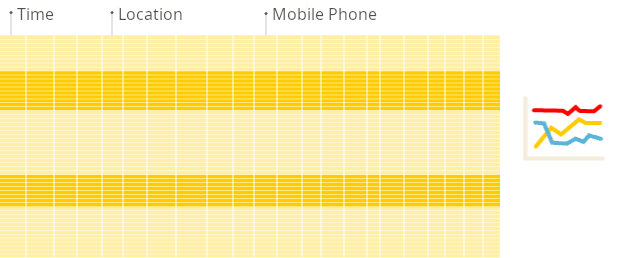
- In a row-oriented database management system (DBMS), data is stored in rows, with all values related to a row stored physically next to each other.
- In a column-oriented DBMS, data is stored in columns, with values from the same columns stored together.
Clickhouse
ClickHouse is a high-performance, column-oriented SQL database management system (DBMS) for online analytical processing (OLAP). It is available as both an open-source software and a cloud offering.
ENGINE MergeTree
- It can be considered ClickHouse's default engine.
- Organizes data by the primary key (sparse index).
- Data can be partitioned (partitions + parts).
- Creation statement:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [[NOT] NULL] [DEFAULT|MATERIALIZED|ALIAS|EPHEMERAL expr1] [COMMENT ...] [CODEC(codec1)] [TTL expr1] [PRIMARY KEY], name2 [type2] [[NOT] NULL] [DEFAULT|MATERIALIZED|ALIAS|EPHEMERAL expr2] [COMMENT ...] [CODEC(codec2)] [TTL expr2] [PRIMARY KEY], ... INDEX index_name1 expr1 TYPE type1(...) [GRANULARITY value1], INDEX index_name2 expr2 TYPE type2(...) [GRANULARITY value2], ... PROJECTION projection_name_1 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY]), PROJECTION projection_name_2 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY]) ) ENGINE = MergeTree() ORDER BY expr [PARTITION BY expr] [PRIMARY KEY expr] [SAMPLE BY expr] [TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx' [, ...] ] [WHERE conditions] [GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ] ] [SETTINGS name=value, ...]- ENGINE — The MergeTree() engine takes no parameters.
- ORDER BY — The sorting key - ClickHouse uses the sorting key to determine how information is stored on disk. It also serves specific functions in MergeTree family engines, such as aggregation key in AggregatingMergeTree or deduplication key in CollapsingMergeTree. It is used as the primary key if PRIMARY KEY is not provided.
- PARTITION BY — The partitioning key. Optional. For example, if partitioning by month is desired: toYYYYMM(date_column), where date_column is of the Date data type. Partitions are named in the "YYYYMM" format.
- PRIMARY KEY — Optional. Always the same or a prefix of the sorting key. In many cases, it is unnecessary to define the PRIMARY KEY; it defaults to ORDER BY. It is used to build the index itself (primary.idx).
When do ORDER BY and PRIMARY KEY differ?
If, for instance, there is a need to add an additional column to an aggregation key, it might be recommended to only modify the ORDER BY (or sorting key) through an ALTER TABLE, keeping the PRIMARY KEY and, consequently, its index file, unchanged. This way, a complete reindexing can be avoided, as the old PK will be a prefix of the new sorting key, an acceptable situation for the engine's operation. Obviously, the strategy will depend on the cardinality and the intended use as a filter for the new column.
Sorting key vs Primary key
Sorting key defines order in which data will be stored on disk, while primary key defines how data will be structured for queries. Usually those are the same (and in this case you can omit PRIMARY KEY expression, Clickhouse will take that info from ORDER BY expression). link
Example
CREATE TABLE my_base_raw.transactions_raw(
`id_transaction` Int64,
`user_id` Int32,
`timestamp` DateTime(3),
`type` String,
`sequence` string,
`amount` Decimal(10,2),
`__ver` Int64) ENGINE = MergeTree()
ORDER BY (id_transaction)
PARTITION BY toYYYYMM(timestamp)
Partitions and Indexes
- Additionally, we can list the different partitions/parts of each table in ClickHouse by querying the system.parts system table.
system.parts.
SELECT
partition,
name,
active
FROM system.parts
WHERE (table = 'transactions_raw') AND (partition = '202310')
Query id: 6b6aa9ec-fc61-4217-bd47-a3c4fd9400b5
┌─partition─┬─name────────────────────────┬─active─┐
│ 202310 │ 202310_4475842_4490464_1414 │ 1 │
│ 202310 │ 202310_4490465_4511646_1317 │ 1 │
│ 202310 │ 202310_4511647_4515242_1330 │ 1 │
│ 202310 │ 202310_4515243_4515584_174 │ 0 │
│ 202310 │ 202310_4515243_4515585_175 │ 0 │
│ 202310 │ 202310_4515243_4515593_183 │ 0 │
│ 202310 │ 202310_4515243_4515594_184 │ 0 │
│ 202310 │ 202310_4515243_4515595_185 │ 1 │
│ 202310 │ 202310_4515595_4515595_0 │ 0 │
│ 202310 │ 202310_4515596_4515596_0 │ 1 │
│ 202310 │ 202310_4515597_4515597_0 │ 1 │
│ 202310 │ 202310_4515598_4515598_0 │ 1 │
│ 202310 │ 202310_4515599_4515599_0 │ 1 │
└───────────┴─────────────────────────────┴────────┘
Breakdown of the part name: 202310_4515243_4515595_185:
202310is the partition name.4515243is the minimum PK number of the data block.4515595is the maximum PK number of the data block.185is the mutation version (if a part has mutated).rte ha mutado).
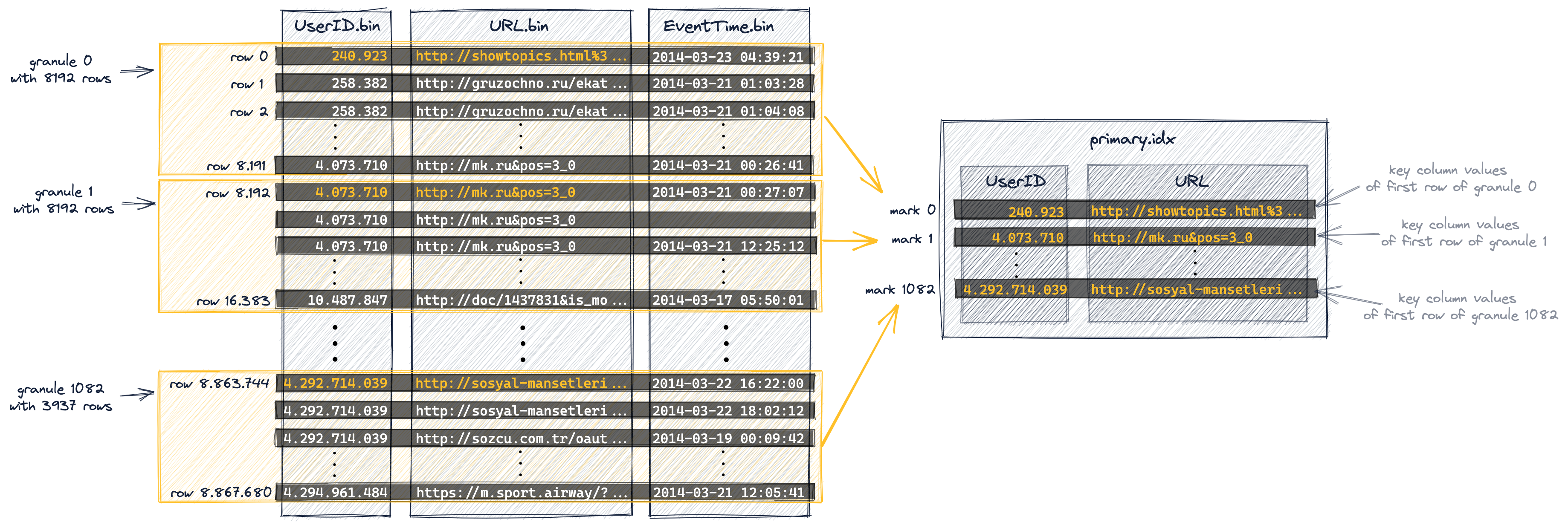
How do sparse indices work?
Given the following index within a partition of a table:  If we use the following filters in the WHERE clause of a query, the initial pruning would be:
If we use the following filters in the WHERE clause of a query, the initial pruning would be:
- CounterID in ('a', 'h') → ranges of marks [0, 3) and [6, 8).
- CounterID IN ('a', 'h') AND Date = 3 → ranges of marks [2, 3) and [7, 8).
- Date = 3 → range of marks [1, 10].
Graphical representation of index and storage strategy
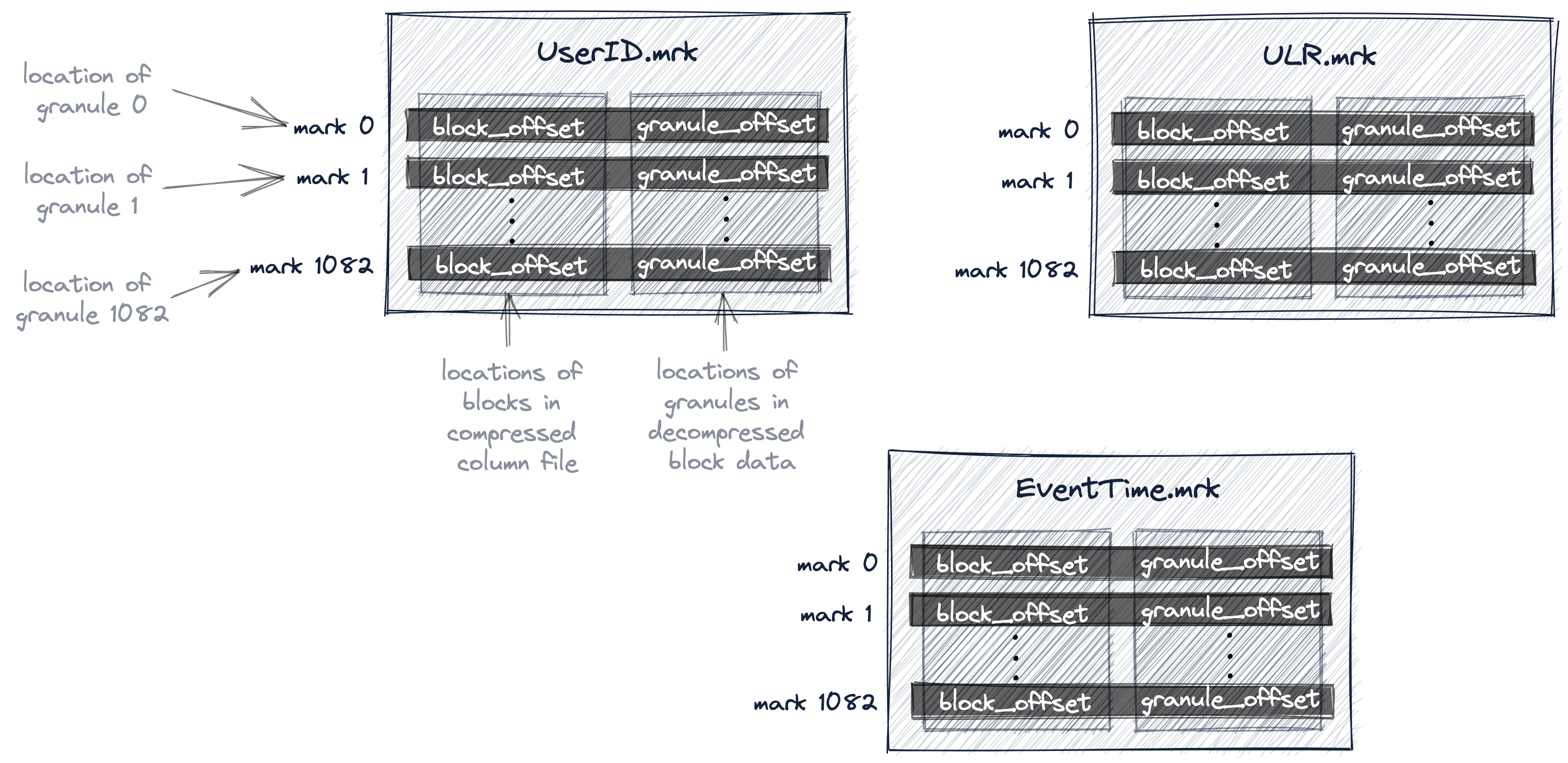
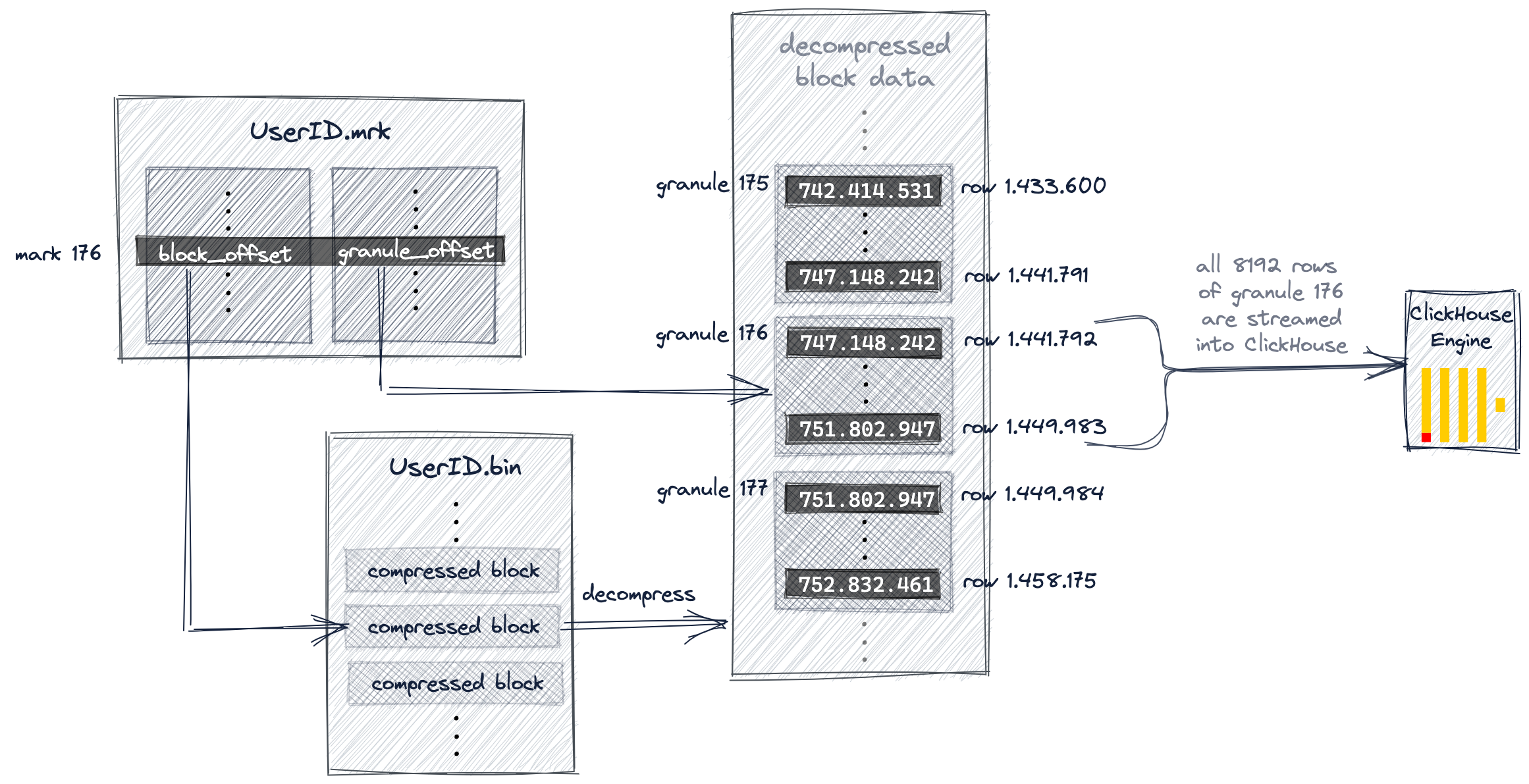
ENGINE Kafka
Tables defined with ENGINE = Kafka act as event consumers in topics and do not serve as permanent storage.
MaterializedViews
In ClickHouse, MaterializedViews function as triggers for the source table of the query, meaning the database offers reactive functionality to new rows Reading